Какие слова индексирует поисковая машина
Как мы уже говорили, для индексации слов на страницах поисковику нужно знать, что именно считается словом.
Что такое слово
Например, слова с дефисом (красно-синий, что-нибудь) — это одно слово или два? А числа — это тоже слова или они выбрасываются, как «мусор»? А слова на другом языке — выбрасывать или оставлять? Что делать с комбинацией букв и цифр (с названиями моделей электроники, например)? Индексируются ли адреса электронной почты, интернет-адреса и даты, и если да, то как?
Все эти вопросы решаются разработчиками каждой поисковой машины по-своему. Более того, нам здесь нет смысла пытаться точно указать правила выделения слов для «Яндекса» или Google — они могут меняться хоть раз в месяц, с каждым вводом «в бой» очередной версии поискового механизма. Гораздо проще это проверять самостоятельно, когда требуется.
Как проверить
Вы сами можете легко проверить, как разработчики «Яндекса», Google или «Рамблера» обрабатывают, например, слова с дефисом или числа — достаточно ввести в поисковик такой запрос и посмотреть, что именно найдет и как покажет поисковая машина. Поскольку отысканные слова показываются и подсвечиваются в цитатах (аннотациях) страниц, сразу будет видно, как хранятся слова в индексе данного поисковика.
Разделители
Конечно, поисковики не индексируют всякие служебные символы, так называемые разделители — пробелы, знаки препинания, а также различные теги и другие конструкции языка HTML.
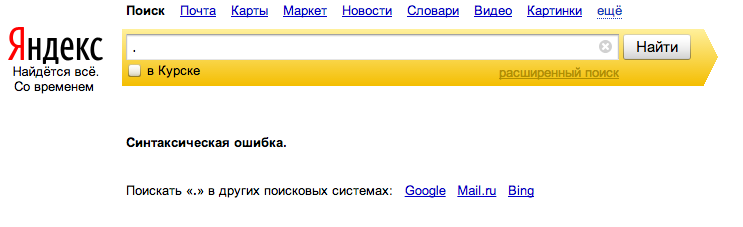
Например, если ввести в «Яндекс» запрос из одной точки . , он откажется искать по такому запросу, еще и сообщит о «синтаксической ошибке». Действительно, точка есть в любом тексте, так что искать ее нет смысла, да и накладно по затратам серверной мощности.
Стоп-слова
А есть ли «ненужные слова», которые поисковики не индексируют вовсе?
Поисковый индекс представляет собой пусть хорошо упакованную, максимально сжатую, «вывернутую наизнанку», но все же копию всех страниц Интернета, известных поисковику. А поисковики стремятся получить данные о максимально большем количестве страниц, то есть в идеале поисковый индекс должен представлять собой копию всего Интернета, а это огромный объем данных.
Поэтому раньше поисковые машины старались экономить место на дисках и время работы сервера и при индексации отбрасывали некоторые неважные, служебные слова, так называемые стоп-слова, например предлоги, союзы, числа, сокращения и т. п., а также и цифры.
В дальнейшем оказалось, что пользователи все-таки достаточно часто запрашивают такие слова, поэтому их нужно хранить (особенно для поиска точных цитат, включающих эти служебные слова). А стоимость хранения мегабайта данных к настоящему времени существенно снизилась — жесткие диски стали дешевы. Так что сейчас большинство популярных поисковиков индексируют все слова в текстах, в том числе и стоп-слова — предлоги, союзы, междометия. Индексируют они также и цифры, и буквенно-цифровые комбинации (т. е. считают их словами). Так что сейчас вы можете поискать в «Яндексе» или «Рамблере», например, предлог «в». Это, кстати говоря, хороший способ прикинуть, сколько всего страниц в индексе поисковика, поскольку данный предлог есть в любом русскоязычном тексте.
| Как устроен индекс поисковой машины | Индексация ссылок |